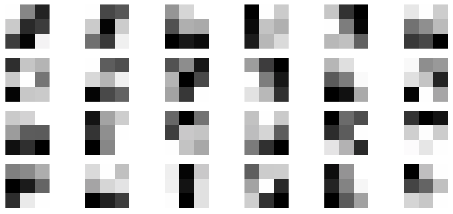
Singular Value Decomposition#
If \(A\) is any \(m \times n\) matrix, then \(AA^T\) and \(A^TA\) are symmetric matrices therefore both are orthogonally diagonalizable, \(AA^T = PD_1P^T\) and \(A^TA = QD_2Q^T\), and these decompositions lead to the singular value decomposition \(A = P \Sigma Q^T\) where \(\Sigma\) is a diagonal \(m \times n\) matrix containing the singular values (the square roots of the eigenvalues in \(D_1\) and \(D_2\)).
SVD Construction#
Throughout this section \(A\) is a real \(m \times n\) matrix.
All eigenvalues of \(AA^T\) and \(A^TA\) are non-negative (that is, \(\lambda \geq 0\)).
Proof
Let \(\lambda\) be an eigenvalue of \(AA^T\) with eigenvector \(\boldsymbol{p}\). Compute
Since \(\boldsymbol{p}\) is a nonzero vector, we can write
therefore \(\lambda\) is a real number squared and must be non-negative. The same calculation works for \(A^TA\).
Let \(\lambda\) be a positive eigenvalue of \(AA^T\) with unit eigenvector \(\boldsymbol{p}\). Then \(\lambda\) is an eigenvalue of \(A^TA\) with unit eigenvector
Conversely, let \(\lambda\) be a positive eigenvalue of \(A^TA\) with (unit) eigenvector \(\boldsymbol{q}\). Then \(\lambda\) is an eigenvalue of \(AA^T\) with eigenvector
Proof
Compute
Therefore \(\boldsymbol{q}\) is an eigenvector for \(A^TA\) with eigenvalue \(\lambda\). Now let’s verify it is a unit vector. Compute
Similar computations prove the second statement regarding \(\boldsymbol{p} = \displaystyle \frac{1}{\sigma} A \boldsymbol{q}\).
The formulas relating \(\boldsymbol{p}\) and \(\boldsymbol{q}\) above for \(\lambda > 0\) imply that the multiplicity of the eigenvalue \(\lambda\) for \(AA^T\) is equal to the multiplicity of the eigenvalue \(\lambda\) for \(A^TA\).
The matrices \(AA^T\) and \(A^TA\) have the same set of positive eigenvalues. Label the eigenvalues in decreasing order \(\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_r > 0\). The singular values of \(A\) are
\(N(AA^T) = N(A^T)\) and \(N(A^TA) = N(A)\).
Proof
If \(\boldsymbol{v} \in N(A^T)\) then \(AA^T \boldsymbol{v} = 0\) and so \(\boldsymbol{v} \in N(AA^T)\) and so \(N(A^T) \subset N(AA^T)\).
Now let \(\boldsymbol{v} \in N(AA^T)\). Compute
Therefore \(A^T \boldsymbol{v} = 0\) and \(\boldsymbol{v} \in N(A^T)\) and so \(N(AA^T) \subset N(A^T)\). Finally, we conclude \(N(AA^T) = N(A^T)\).
Similar computations prove the statement \(N(A^TA) = N(A)\).
Let \(A\) be an \(m \times n\) matrix and let \(\sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_r > 0\) be the singular values of \(A\). There exist orthogonal matrices \(P\) and \(Q\) such that
Proof
The matrix \(A^TA\) is a \(n \times n\) symmetric matrix and is therefore orthogonally diagonalizable. Let \(\boldsymbol{q}_1,\dots,\boldsymbol{q}_n\) be orthonormal eigenvectors of \(A^TA\) chosen in order such that
Note that \(\boldsymbol{q}_{r+1},\dots,\boldsymbol{q}_r \in N(A)\). Let \(Q\) be the orthogonal matrix
The matrix \(AA^T\) is a \(m \times m\) symmetric matrix and is therefore orthogonally diagonalizable. Let
Each \(\boldsymbol{p}_1,\dots,\boldsymbol{p}_r\) is a unit eigenvector for \(AA^T\) with eigenvalue \(\lambda_i\). Find an orthonormal basis \(\boldsymbol{p}_{r+1},\dots,\boldsymbol{p}_m\) of the nullspace \(N(A^T)\). Then \(\boldsymbol{p}_1,\dots,\boldsymbol{p}_m\) are orthonormal eigenvectors for \(AA^T\). Define the orthogonal matrix
Compute
Finally, compute
Therefore \(AQ = P \Sigma\) and so \(A = P \Sigma Q^T\).
The equation \(A = P \Sigma Q^T\) is called the singular value decomposition of \(A\), the diagonal entries of \(\Sigma\) are the singular values, the columns of \(P\) are called the left singular vectors and the columns of \(Q\) are called the right singular vectors.
In the construction of the SVD, we may chose to first construct either \(P\) or \(Q\). The connection between the columns for \(i = 1,\dots,r\) are given by the equations:
Construct the SVD for
Since \(A^TA\) is a smaller matrix, let us first construct \(Q\). Compute
Therefore \(\sigma_1 = \sqrt{3}\) and \(\sigma_2 = \sqrt{2}\). By inspection, we find
Construct the matrix \(P\)
Extend to an orthonormal basis of \(\mathbb{R}^3\) by finding \(\boldsymbol{p}_3\) orthogonal to \(\boldsymbol{p}_1\) and \(\boldsymbol{p}_2\). There are different ways of doing this. Setup equations \(\langle \boldsymbol{p}_1 , \boldsymbol{p}_3 \rangle = 0\) and \(\langle \boldsymbol{p}_2 , \boldsymbol{p}_3 \rangle = 0\) in a linear system and solve
Therefore the SVD is given by
Corollaries of SVD#
Let \(A = P \Sigma Q^T\).
\(N(A) = \mathrm{span} \{ \boldsymbol{q}_{r+1},\dots,\boldsymbol{q}_n \}\)
\(R(A) = \mathrm{span} \{ \boldsymbol{p}_1,\dots,\boldsymbol{p}_r \}\)
\(N(A^T) = \mathrm{span} \{ \boldsymbol{p}_{r+1},\dots,\boldsymbol{p}_m \}\)
\(R(A^T) = \mathrm{span} \{ \boldsymbol{q}_1,\dots,\boldsymbol{q}_r \}\)
\(\mathrm{rank}(A) = r\)
Let \(\sigma_1\) be the largest singular value of \(A\). Then \(\| A \| = \sigma_1\).
Proof
Since \(P\) is an orthogonal matrix \(\| P \Sigma Q^T \boldsymbol{x} \| = \| \Sigma Q^T \boldsymbol{x} \|\) for all \(\boldsymbol{x}\). Compute from the definition
Let \(\boldsymbol{y} = Q^T \boldsymbol{x}\) and write the equation
Since \(\Sigma\) is a diagonal matrix we know that \(\| \Sigma \|\) is equal to the absolute value of the maximum of the diagonal entries and so \(\| A \| = \sigma_1\).
Let \(A\) be a \(n \times n\) invertible matrix. Let \(\sigma_1\) be the largest singular value of \(A\) and let \(\sigma_n\) be the smallest. Then \(\| A^{-1} \| = 1/\sigma_n\) and \(\mathrm{cond}(A) = \frac{\sigma_1}{\sigma_n}\).
Proof
Let \(\sigma_1 \geq \cdots \geq \sigma_n\) be the singular values of \(A\). The singular values of \(A^{-1}\) in decreasing order are \(1/\sigma_n \geq \cdots \geq 1/\sigma_1\) therefore \(\| A^{-1} \| = 1/\sigma_n\) and finally
Principal Component Analysis#
Let \(\boldsymbol{x}_1 , \dots , \boldsymbol{x}_n \in \mathbb{R}^p\) (viewed as row vectors) and let \(X\) be the \(n \times p\) data matrix where row \(k\) is given by \(\boldsymbol{x}_k\). Assume the data is normalized such that the mean value of each column of \(X\) is 0. The unit vector \(\boldsymbol{w}_1\) which maximizes the sum
is called the first weight vector of \(X\) (see Wikipedia:Principal component analysis). More generally, given weight vectors \(\boldsymbol{w}_1 , \dots, \boldsymbol{w}_{k-1}\), the \(k\)th weight vector of \(X\) is the unit vector \(\boldsymbol{w}_k\) which maximizes
where \(X_k\) is the projection of the data matrix \(X\) onto \(\mathrm{span} \{ \boldsymbol{w}_1 , \dots, \boldsymbol{w}_{k-1} \}^{\perp}\)
The projection coefficient \(\langle \boldsymbol{x}_i , \boldsymbol{w}_k \rangle\) is called the \(k\)th principal component of a data vector \(\boldsymbol{x}_i\).
Each \(\langle \boldsymbol{x}_k , \boldsymbol{w}_1 \rangle^2\) is the length squared of the orthogonal projection of \(\boldsymbol{x}_k\) onto \(\boldsymbol{w}_1\). Therefore the first weight vector \(\boldsymbol{w}_1\) points in the direction which captures the most information (ie. the maximum variance) of the data, and the second weight vector \(\boldsymbol{w}_2\) is orthogonal to \(\boldsymbol{w}_1\).
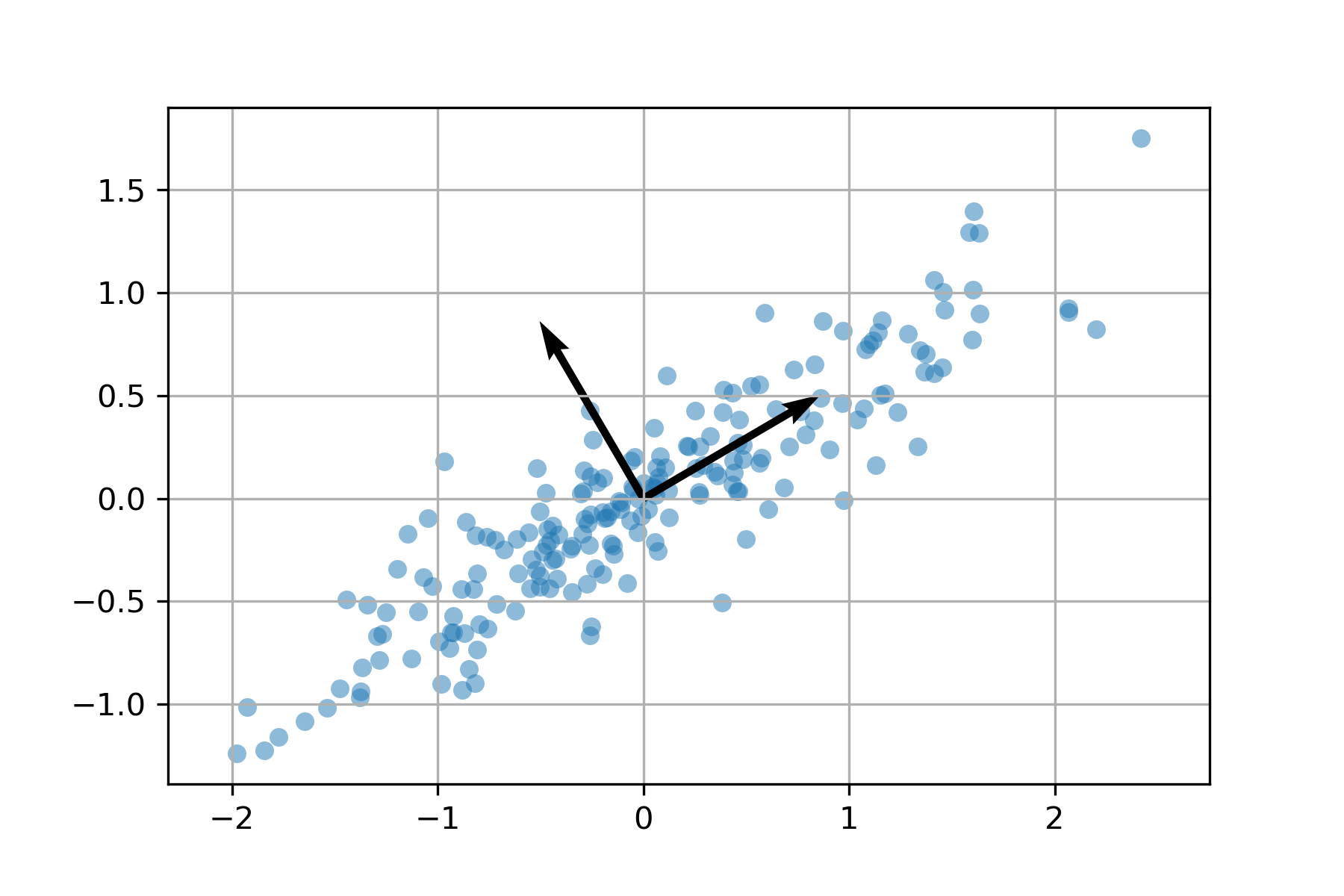
The weight vectors \(\boldsymbol{w}_1 , \dots , \boldsymbol{w}_p\) are the right singular vectors of the matrix \(X\). In other words, let \(X = P \Sigma Q^T\) be a singular value decomposition of \(X\) and let \(\boldsymbol{q}_1, \dots, \boldsymbol{q}_p\) be the columns of \(Q\) corresponding to singular values \(\sigma_1 > \cdots > \sigma_p > 0\). Then \(\boldsymbol{w}_1 = \boldsymbol{q}_1 , \dots , \boldsymbol{w}_p = \boldsymbol{q}_p\).
Proof
Let \(X = P \Sigma Q^T\) be a singular value decomposition of \(X\). We know that \(\| X \| = \sigma_1\) where \(\sigma_1\) is the largest singular value of \(X\) and therefore the first weight vector will satisfy \(\| X \boldsymbol{w}_1 \| = \sigma_1\). Note that
Since \(\Sigma\) is diagonal with diagonal entires \(\sigma_1 \geq \cdots \geq \sigma_p\), the maximum value of \(\| X \boldsymbol{w} \|\) occurs when
therefore \(\boldsymbol{w}_1 = \boldsymbol{q}_1\). For general \(k\), note that the singular value decomposition \(X_k = P_k \Sigma_k Q^T_k\) is obtained from \(X\) by removing the singular values \(\sigma_1,\dots,\sigma_{k-1}\). Therefore the largest singular value of \(X_k\) is \(\sigma_k\) with corresponding right singular vector \(\boldsymbol{q}_k\) and therefore \(\boldsymbol{w}_k = \boldsymbol{q}_k\).
Find the first weight vector for the data given in the image below.
We expect
since that direction clearly captures the most information. Form the data matrix
We don’t need to compute the full SVD of \(X\) but just the first right singular vector. Compute
The characteristic polynomial of \(X^TX\) is
The right singular vector \(\boldsymbol{q}_1\) for \(X\) is a unit eigenvector for \(X^TX\) for the eigenvalue \(\lambda_1 = 20\). Compute
The digits dataset from sklearn is a \(1797 \times 64\) data matrix \(X\) such that each row represents an \(8 \times 8\) pixel image of a handwritten number. The first 10 rows of X (reshaped from vectors of length 64 to \(8 \times 8\) matrices to visualize) are:
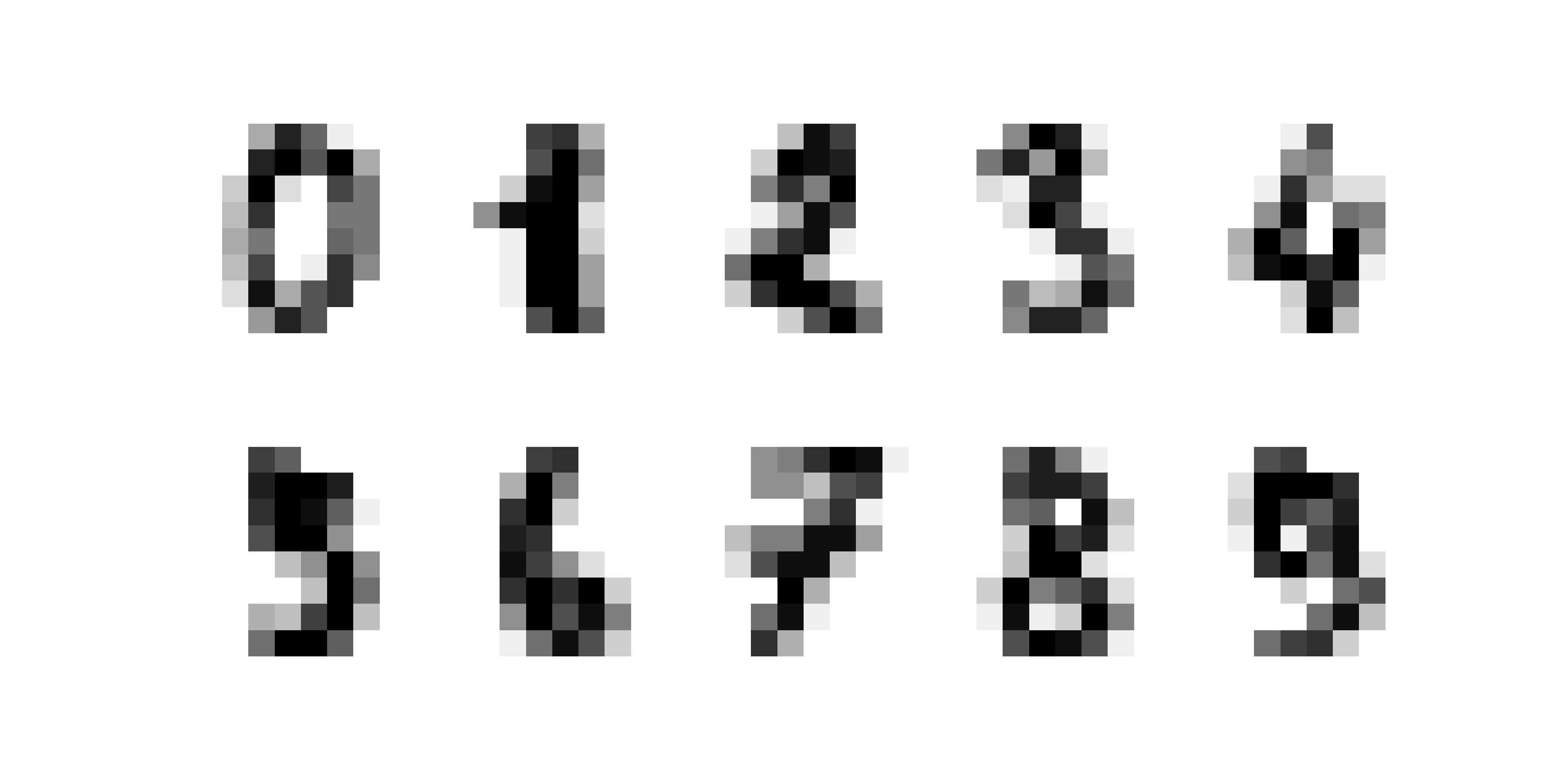
Compute the first 2 weight vectors and find (again \(\boldsymbol{w}_1,\boldsymbol{w}_2\) reshaped from vectors of length 64 to \(8 \times 8\) matrices to visualize)
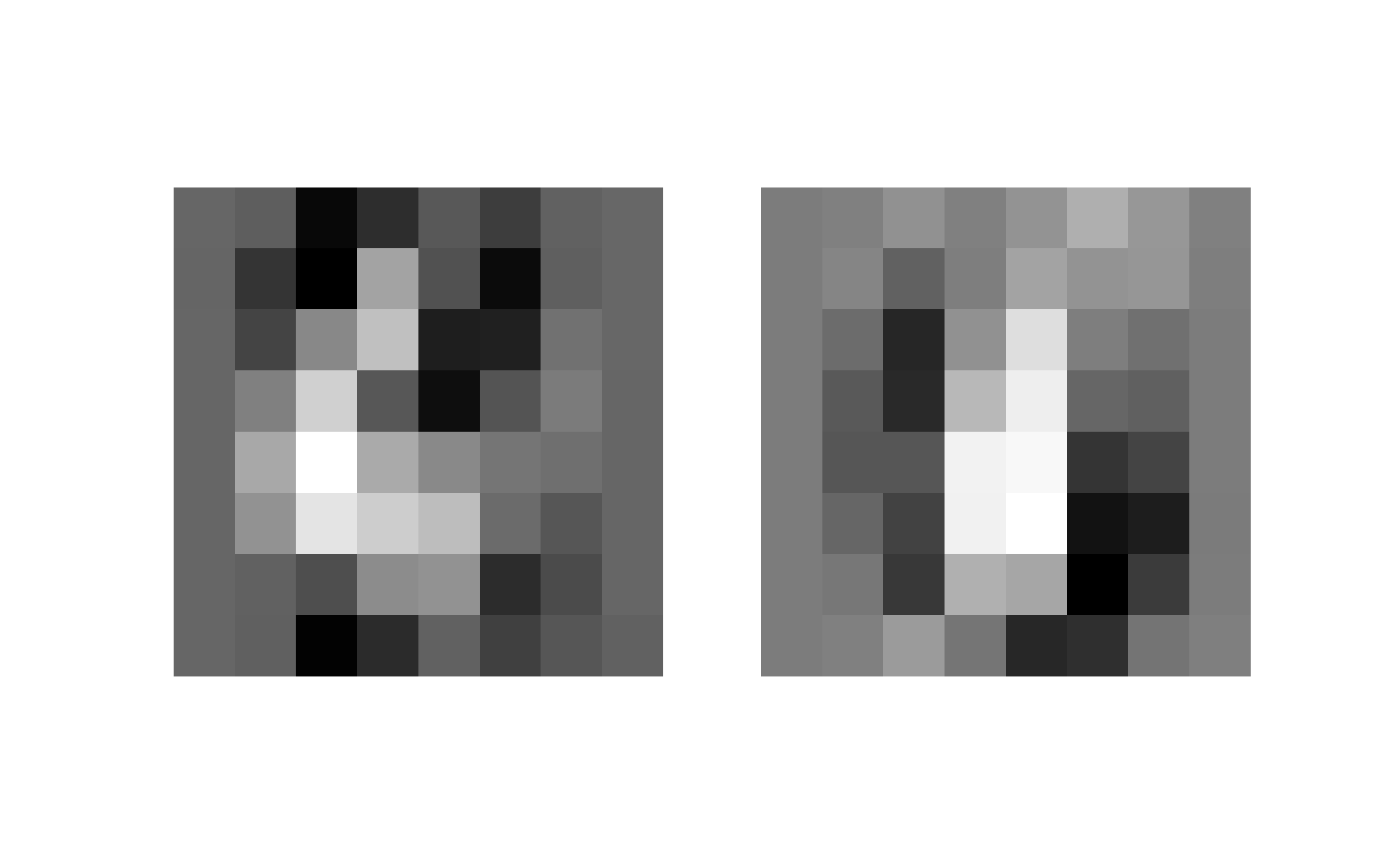
We can see \(\boldsymbol{w}_1\) looks like a 3 and \(\boldsymbol{w}_2\) looks like 0. Project the entire dataset onto these weight vectors and label each data point by a color according to the digit:
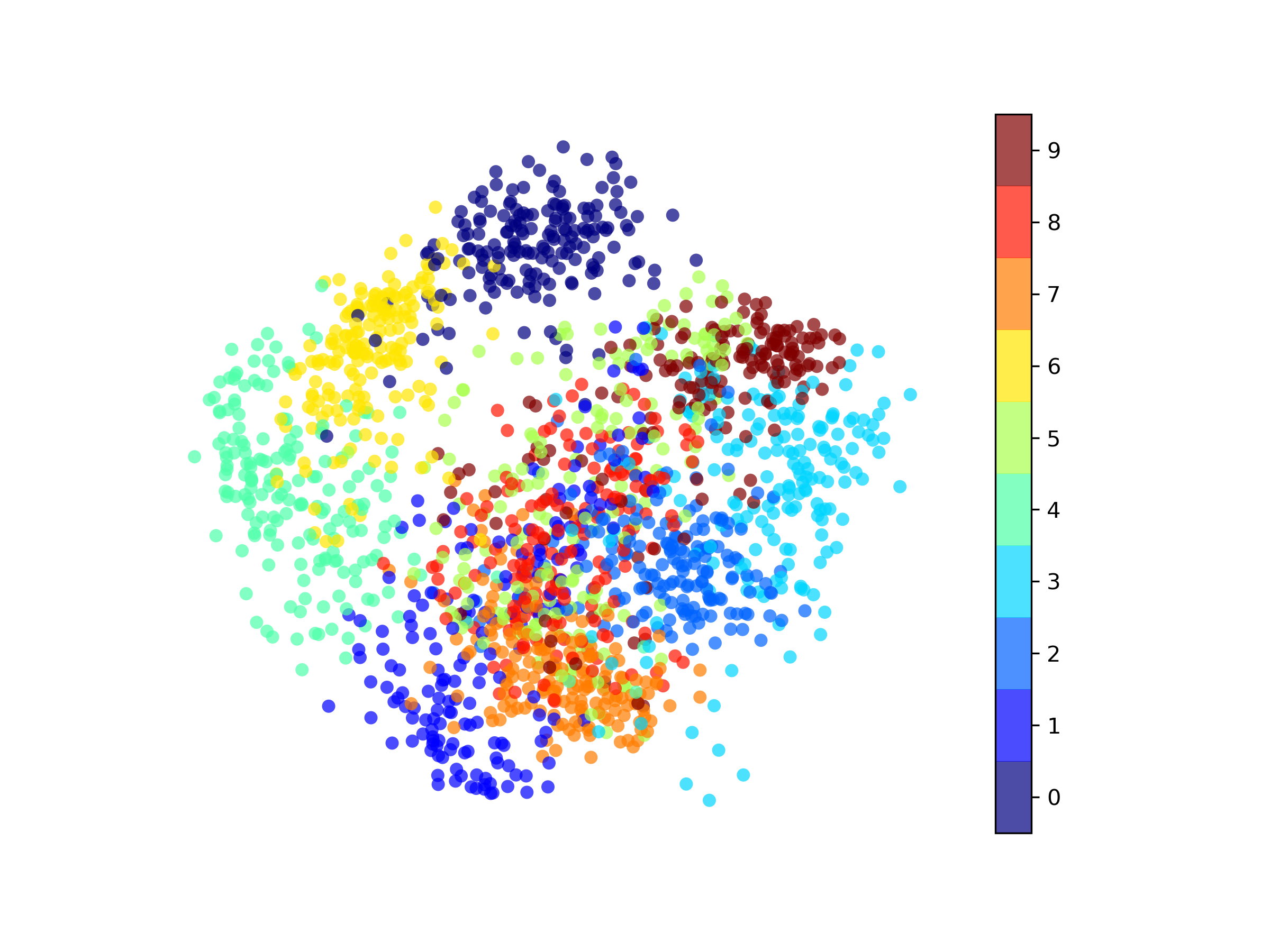
We can see that the 3s are to the right in the horizontal direction since these points most similar to \(\boldsymbol{w}_1\), and the 0s are at the top in the vertical direction since these points most similar to \(\boldsymbol{w}_2\). We can make other interesting observations such as the 4s are opposite to the 3s and orthogonal to 0s, and 7s and 1s are opposite to 0s and orthogonal to 3s.
Pseudoinverse and Least Squares#
Let \(A\) be a \(m \times n\) matrix such that \(\mathrm{rank}(A) = r\) and let \(A = P \Sigma Q^T\). The pseudoinverse of \(A\) is \(A^+ = Q \Sigma^+ P^T\) where
If \(A\) is invertible, then \(A^+ = A^{-1}\).
Let \(A\) be an \(m \times n\) matrix with \(\mathrm{rank}(A) = n\) and let \(\boldsymbol{b} \in \mathbb{R}^m\). The least squares approximation of the system \(A \boldsymbol{x} \cong \boldsymbol{b}\) is given by \(\boldsymbol{x} = A^+ \boldsymbol{b}\).
Proof
Let \(P^T \boldsymbol{b} = \boldsymbol{c}\) and write
Since \(P\) is an orthogonal matrix we have
The matrix \(\Sigma\) is of the form
and so only the first \(n\) entries of \(\Sigma \boldsymbol{v}\) are nonzero for any vector \(\boldsymbol{v} \in \mathbb{R}^n\). Therefore the minimum value \(\| A \boldsymbol{x} - \boldsymbol{b} \| = \| \Sigma Q^T \boldsymbol{x} - \boldsymbol{c} \|\) occurs when
and so \(\boldsymbol{x} = Q \Sigma^+ \boldsymbol{c}\). Altogether, we have \(\boldsymbol{x} = Q \Sigma^+ P^T \boldsymbol{b} = A^+ \boldsymbol{b}\).
\(AA^+\) is the projection matrix onto \(R(A)\) and \(A^+A\) is the projection onto \(R(A^T)\).
Proof
Compute \(AA^+ = P \Sigma Q^T Q \Sigma^+ P^T = P \Sigma \Sigma^+ P^T\) and note
where \(I_r\) is the identity of matrix of size \(r\). Let
where \(\boldsymbol{p}_1,\dots,\boldsymbol{p}_r\) are the first \(r\) columns of \(P\). By definition, the projection matrix onto \(R(A)\) is \(P_r P_r^T\) and we want to show that \(P \Sigma \Sigma^+ P^T = P_r P_r^T\). Equivalently, we can show that \(P \Sigma \Sigma^+ = P_r P_r^T P\). Multiplying everything out shows that
and also
therefore \(AA^+ = P_rP_r^T\) is the projection matrix onto \(R(A)\). Similar computations show that \(A^+A\) is the projection onto \(R(A^T)\).
\(AA^+A = A\) and \(A^+AA^+=A^+\).
Proof
Compute
Similar computations show \(A^+AA^+=A^+\).
SVD Expansion#
Let \(A\) be a \(m \times n\) matrix such that \(\mathrm{rank}(A) = r\) and \(A = P \Sigma Q^T\) be the singular value decomposition. Then
where \(\boldsymbol{p}_1,\dots,\boldsymbol{p}_r\) are the first \(r\) columns of \(P\), and \(\boldsymbol{q}_1,\dots,\boldsymbol{q}_r\) are the first \(r\) columns of \(Q\).
Proof
Let \(B = \sum_{i=1}^r \sigma_i \boldsymbol{p}_i \boldsymbol{q}_i^T\) and we will show that \(AQ = BQ\) and therefore \(A=B\). By the construction of the SVD we know that
and
therefore
The vectors \(\boldsymbol{q}_1,\dots,\boldsymbol{q}_n\) are orthonormal therefore
and
therefore
Finally, \(AQ=BQ\) therefore \(A = B\).
The SVD expansion of \(A\) is
Note that each outer product \(\boldsymbol{p}_i \boldsymbol{q}_i^T\) is a \(m \times n\) matrix of rank 1.
Let \(A = P \Sigma Q^T\). The truncated SVD expansion of rank \(k\) of \(A\) is
Suppose we want to solve the system \(A \boldsymbol{x} = \boldsymbol{b}\) however the right side is corrupted by noise \(\boldsymbol{e}\) and we must work with the system
Solving directly we get
and the term \(A^{-1}\boldsymbol{e}\) is called the inverted noise which may dominate the true solution \(\boldsymbol{x} = A^{-1} \boldsymbol{b}\). From the SVD expansion, we see that most of \(A\) is composed of the terms \(\sigma_i \boldsymbol{p}_i \boldsymbol{q}_i^T\) for large singular values \(\sigma_i\). If we know that the error \(\boldsymbol{e}\) is unrelated to \(A\) in the sense that \(\boldsymbol{e}\) is (mostly) orthogonal to the singular vectors \(\boldsymbol{p}_i\) of \(A\) corresponding to large singular values, then the truncated SVD expansion of the pseudoinverse
gives a better solution
since the term \(A^+_k\boldsymbol{e}\) will be smaller. In other words, we avoid terms \(\sigma_i^{-1} \boldsymbol{p}_i \boldsymbol{q}_i^T\) in the SVD expansion of \(A^{-1}\) for small singular values \(\sigma_i\) which produce large values \(\sigma_i^{-1}\) which may amplify the error. This is the strategy for image deblurring and computed tomography in the next sections.
Exercises#
Find the singular value decomposition of the matrix
Solution
Find the singular value decomposition of the matrix
Solution
Let \(X\) be a \(n \times p\) (normalized) data matrix, let \(\boldsymbol{x}_i , \boldsymbol{x}_j \in \mathbb{R}^p\) be two different rows of \(X\) and let \(\boldsymbol{w}_1\) be the first weight vector of \(X\). Determine whether the statement is True or False.
If \(\| \boldsymbol{x}_i \| < \| \boldsymbol{x}_j \|\) then \(| \langle \boldsymbol{x}_i , \boldsymbol{w}_1 \rangle | < | \langle \boldsymbol{x}_j , \boldsymbol{w}_1 \rangle |\).
If \(\langle \boldsymbol{x}_i , \boldsymbol{x}_j \rangle = 0\) and \(\langle \boldsymbol{x}_i , \boldsymbol{w}_1 \rangle = 0\) then \(\langle \boldsymbol{x}_j , \boldsymbol{w}_1 \rangle = 0\).
Solution
False
False
Let \(X\) be a \(n \times 2\) data matrix and let \(Y\) be the matrix with the same columns as \(X\) but switched. In other words, the first column of \(Y\) is the same as the second column of \(X\), and the second column of \(Y\) is the first column of \(X\). Determine whether the statement is True or False.
If \(X\) and \(Y\) represent the same set of data points, then all the singular values of \(X\) equal.
If \(X\) and \(Y\) represent the same set of data points, then \(\boldsymbol{w}_1 = \begin{bmatrix} 1/\sqrt{2} & 1/\sqrt{2} \end{bmatrix}^T\).
Solution
True
False
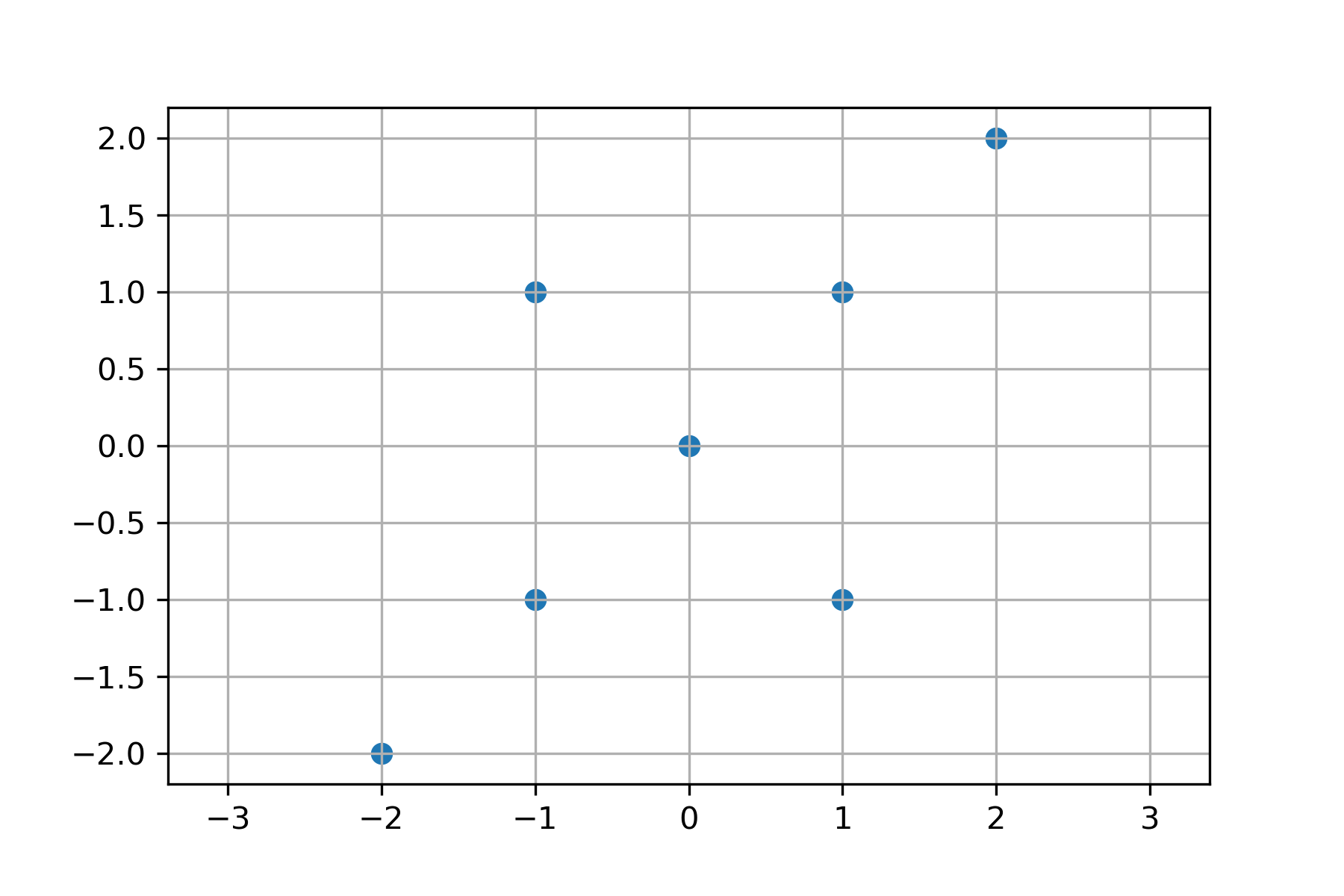
Find the weight vectors for the data matrix \(X\) representing the points:
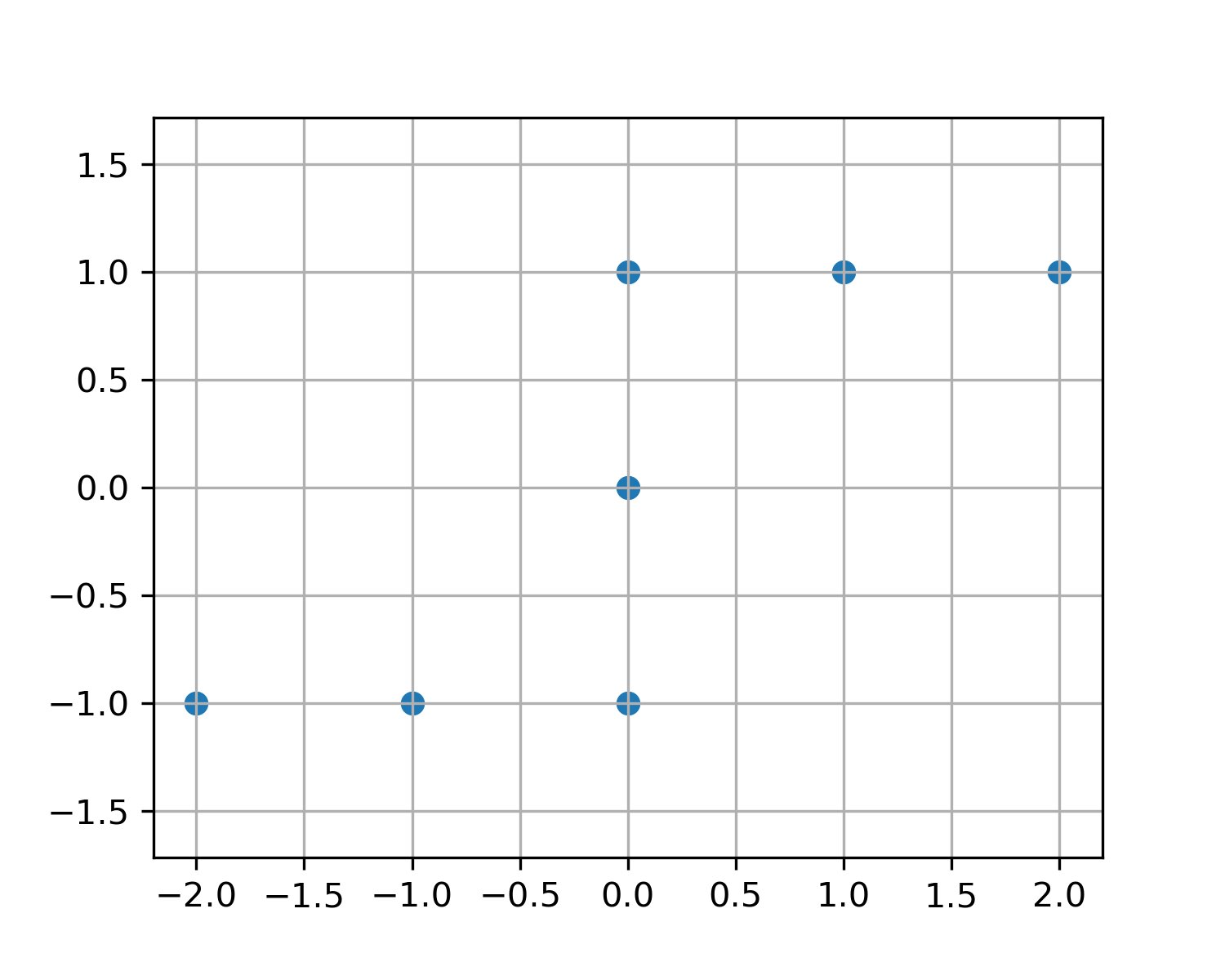
Solution
Suppose \(X\) is a \(100 \times 4\) data matrix such that
Find all the weight vectors of \(X\).
Suppose we want to solve a system \(A \boldsymbol{x} = \boldsymbol{b}\). A small change \(\Delta \boldsymbol{b}\) produces a change in the solution
Describe the unit vector \(\Delta \boldsymbol{b}\) that will produce the largest change \(\| \Delta \boldsymbol{x} \|\).
Find the rank 2 pseudo inverse
of the matrix
(Note: the columns of \(A\) are orthogonal.)
Let \(A\) be a \(m \times n\) matrix with singular value decomposition \(A = P \Sigma Q^T\). Let \(k < \min\{m,n\}\) and let
Describe the singular value decomposition of \(A - A_k\).